Pruna AI, a European startup specializing in AI model optimization, has announced that it will open-source its optimization framework. This framework integrates various efficiency techniques such as caching, pruning, quantization, and distillation, which collectively enhance the performance of AI models. John Rachwan, co-founder and CTO of Pruna AI, emphasized the innovation behind the framework, highlighting its ability to standardize the processes for saving, loading, and evaluating compressed models.
Traditionally, big AI labs like OpenAI have relied on compression methods, with notable examples including the development of GPT-4 Turbo, a streamlined iteration of its predecessor. In this context, Pruna AI aims to fill a gap in the open-source landscape by consolidating multiple compression techniques into a user-friendly tool, setting a new standard for efficiency methods in AI.
Rachwan noted that most existing open-source solutions tend to focus on singular methods, making it challenging for developers to adopt a holistic approach. “Pruna aims to aggregate all techniques, making them easy to use together,” he stated. This ambitious goal could revolutionize how AI developers optimize their models, enhancing efficiency across various applications.
The versatility of Pruna AI’s framework extends to a wide range of models, including large language, diffusion, speech-to-text, and computer vision models. However, the company’s current focus leans towards image and video generation. Among its users are well-known entities like Scenario and PhotoRoom, who are already leveraging the compression capabilities of Pruna AI.
Additionally, Pruna AI is poised to introduce an advanced enterprise edition of its framework. This version will feature a compression agent, allowing users to input their model specifications and desired performance levels. The agent will then autonomously determine the optimal compression strategy, significantly streamlining the process for developers.
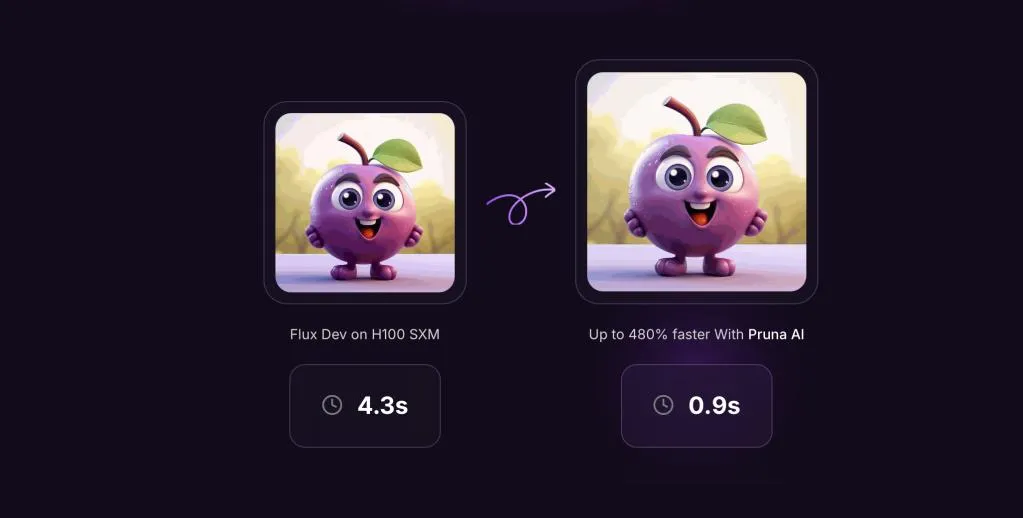
Pruna AI’s payment model is usage-based, similar to GPU rentals on cloud platforms, allowing clients to scale their costs with the level of service they require. This structure becomes particularly vital for organizations whose AI infrastructure hinges on effective model optimization. Demonstrative of its capabilities, the company has successfully engineered a reduction in Llama model size by a factor of eight with minimal impact on performance.
With a recent seed funding round securing $6.5 million, backed by investors like EQT Ventures and Daphni, Pruna AI is poised for growth. Their efforts aim to position their open-source framework as a valuable investment for AI developers seeking efficiency and cost savings.